Support Vector Machine |
Support vector machine (SVM) is a useful and very popular technique for data classification, regression and probability density estimation.
In most simplified way the SVM can be described as discriminative supervised classifier. In other words, entire sequencing consists of two separate procedures: classifier training procedure on the known data set and new unknown data classification procedure.
The training procedure usually includes such steps as data normalization, model parameters estimation and model building. Sometimes train procedure can take long time, so usually the last sub step is model saving. The saved model can be loaded before classification procedure.
The classification procedure includes data normalization and prediction value estimation.
The main idea of SVM is to split observations by separating hyperplane with the maximum margin.
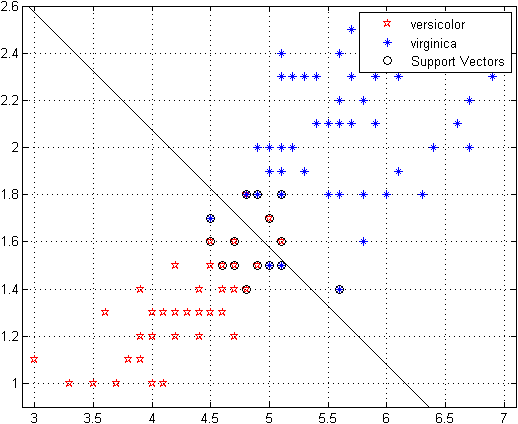
This topic contains the following sections:
To make the separating function more sophisticated the non-linear kernel function can be used. The kernel function transforms the raw observations to some other feature space, where the linear separation can be performed. So, the kernel parameters can be expressed as free dimensions for linear space separation.
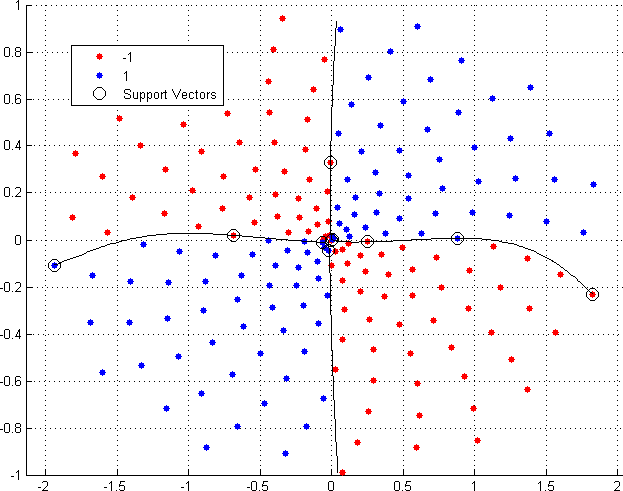
The library supports the following kernel functions via SVMKernelBase enumeration:
Kernel function | 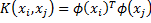 | Corresponding library class |
|---|---|---|
Linear kernel | 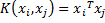 | |
Polynomial kernel | 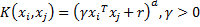 | |
Radial basis function (Gaussian) kernel | 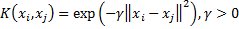 | |
Sigmoid kernel | 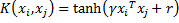 |
The library supports classification models (with optional probability estimation), data regression models and density estimation models.
IBaseClassifier interface is inherited by other machine learning classes and features the following methods:
The following methods of SVM class are used to save, load, and clear model:
Method | Description | Performance |
|---|---|---|
save | Save model to files. | |
load | Load model from files. | |
clear | Delete model. |
